

Directions (1 -2): A shopkeeper have two articles A & B. Marked price of article B is 20% more than marked price of article A, shopkeeper sold article A at 25% discount and article B at 20% discount, if he made 20% loss on article A and 6⅔% profit on article B and total loss of shopkeeper was Rs. 1785.
Q1. If shopkeeper want 25% profit on article A, then find at what price shopkeeper should sold the article?
(a) 16206.25 Rs.
(b) 16200. 25Rs.
(c) 16180.25 Rs.
(d) 16406.25 Rs.
(e) 16160.25 Rs.
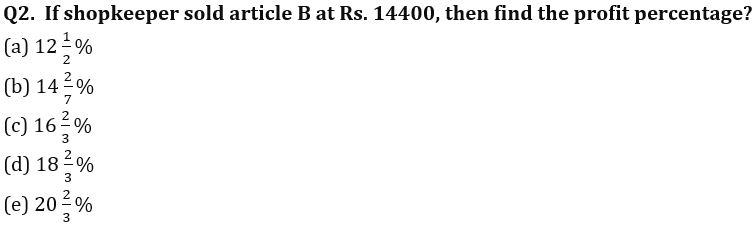
Directions (3-4): A person invested Rs. 20000 in a bank which is offering 10% per annum simple interest. After two years he withdrew the money from the bank and deposited the total amount in another bank which gives an interest rate of r% p.a. compounded annually. After 2 years he received an amount of Rs. 2460 more than what he had invested in that bank.
Q3. What is the value of r?
(a) 10%
(b) 15%
(c) 5%
(d) 12%
(e) None of these
Q4. If the person had invested Rs. 50,000 instead of 20000 in the bank that offered simple interest, what would have been his net profit after following the same procedure as given above?
(a) Rs. 16,800
(b) Rs. 16,150
(c) Rs. 16,350
(d) Rs. 16,000
(e) None of these
Q5. Find the probability of selecting an even number from an arithmetic progression of integers in which total number of digits is even? (Given- Common difference is also integers)
(a) 5/8
(b) cannot be determined
(c) 1/4
(d) 1/2
(e) 3/8

DIRECTIONS ( 7-8): A hollow cylinder, opened from both ends is having inner radius 7 cm, height 14 cm and thickness 1 cm.
Q7. If this cylinder is to be melted to form identical spheres of radius 2.1 cm. How many spheres could be formed approximately?
(a) 28
(b) 17
(c) 21
(d) 29
(e) 25
Q8. If this hollow cylinder is melted and casted into a solid(not hollow) cube. Find the side[approximate] of cube formed?
(a) 3.26
(b) 4.18
(c) 2.75
(d) 8.70
(e) 10.12
DIRECTIONS (9-10): Time taken by a boat to cover a distance while travelling in downstream is 30 second. Average speed of boat after completing around trip of same distance is 24 ms¯¹.
Q9. If the ratio of speed of boat in downstream to that in still water is 6 : 5, then calculate the distance for downstream.
(a) 900 m
(b) 600 m
(c) 1500 m
(d) 1800 m
(e) 1400 m
Q10. On a particular day, boat have to make a round trip of this distance, it started along the downstream but the moment boat covered 1 side distance, water become still. Find the % reduction in time taken on that day with respect to usual days. Assume speed of water and boat from previous questions.
(a) 15%
(b) 16%
(c) 20%
(d) 12%
(e) 10%
Solutions



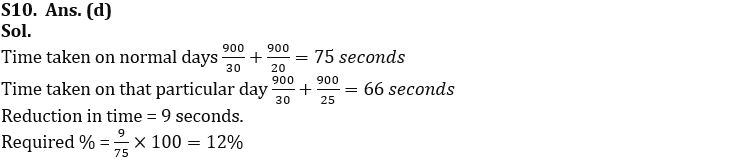









 Quantitative Aptitude Quiz For Bank Main...
Quantitative Aptitude Quiz For Bank Main...
 Quantitative Aptitude Quiz For Bank Foun...
Quantitative Aptitude Quiz For Bank Foun...


